Processamento de texto com Java
Java oferece um conjunto completo de funcionalidades para manipulação de caracteres e este artigo mostra de forma concisa e prática algumas dessas facilidades. Atualmente, Java e Python têm sido bastante usadas para processamento de texto, quando tratamos de cenários com um grande volume de dados.
Seguem alguns exemplos de projetos escritos em Java e que fazem processamento de grande quantidade de dados, textuais ou não:
- Lucene
- Hadoop
- Mahout
- Storm
- OpenNLP
Introdução
O processamento de texto é uma área que vem crescendo, principalmente impulsionado pelas redes sociais, onde os dados não são estruturados como em um banco de dados relacional. Dados não tabelados, que anteriormente eram ignorados, têm hoje uma grande importância no mundo corporativo. O cruzamento de informações está se mostrando uma área lucrativa, por exemplo, no mundo financeiro. Mas todas as corporações podem se beneficiar. A análise do que está sendo produzido em uma organização pode revelar padrões, e essa informação muitas vezes não está gravada em tabelas.
Para ilustrar, vamos criar uma aplicação de exemplo que faz processamento de uma grande quantidade de dados. Esta aplicação vai utilizar os dados da Wikipedia, que disponibiliza uma versão grátis do seu conteúdo. A versão mais recente está disponível aqui.
Modelo de página da Wikipedia:
O arquivo compactado deve ter aproximadamente 1GB e, após descompactado, deve ter algo em torno de 4GB. Ele contém todas as páginas da Wikipedia em português, mas apenas a última revisão, sem o histórico de alterações. Lembre-se que a Wikipedia é colaborativa e todos podem alterar as páginas livremente. Podemos fazer o download da versão completa, com o histórico de versões e outras opções aqui.
No final do texto de cada atributo “text” de uma página da Wikipedia há uma seção onde estão as categorias do artigo. Cada artigo tem uma ou várias categorias. Uma categoria é na verdade outra página, seguindo o modelo de hiperlinks.
Exemplo:
[[Categoria:Geomática]]
[[Categoria:Astronomia|Cronologia ]]
[[Categoria:Efemérides]]
[[Categoria:Calendários]]
2. O projeto
O projeto com o código-fonte está disponível no Github e utiliza as seguintes tecnologias:
- XML (SAX)
- StringBuilder
- JDBC
- Expressões regulares
- Maven
- MySQL
3. SAX
Com a API Simple API for XML, ou SAX, podemos construir um parser mais rápido e que utiliza menos memória que o DOM, Document Object Model, outra API bastante popular para XML. Dessa forma, é melhor usar SAX para arquivos grandes. O DOM carrega todo o conteúdo do arquivo em memória, e nesse caso estamos trabalhando com um arquivo de 4GB.
Para analisar um documento XML com SAX precisamos implementar ao menos os métodos:
- startElement() e endElement(): métodos chamados no começo e fim de cada elemento do documento XML.
- characters(): método chamado com o conteúdo de cada elemento, indicando a posição inicial e final de cada elemento.
O processamento é feito em quatro etapas:
- Primeiro, as páginas são extraídas do XML com SAX.
- Em seguida cada item é inserido no banco de dados através de JDBC.
- Processar cada página e extrair as categorias.
- Inserir as categorias no MySQL.
Cada item do XML é uma página da Wikipedia. Nesta aplicação vamos usar apenas alguns dos atributos. O script para geração das tabelas no MySQL com os atributos que precisamos está logo abaixo.
4. Scripts
O scripts abaixo são para o MySQL.
CREATE TABLE `PaginaWikipedia` (
`id` int(11) NOT NULL DEFAULT '0',
`title` varchar(255) DEFAULT NULL,
`timestamp` datetime DEFAULT NULL,
`username` varchar(255) DEFAULT NULL,
`text` longtext,
`model` varchar(255) DEFAULT NULL,
`format` varchar(255) DEFAULT NULL,
`comment` longtext,
PRIMARY KEY (`id`),
UNIQUE KEY `id_UNIQUE` (`id`)
)
CREATE TABLE `Categoria` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`descricao` text,
PRIMARY KEY (`id`),
UNIQUE KEY `id_UNIQUE` (`id`)
)
5. Código-fonte
As classes Java que representam essas tabelas estão logo abaixo. Crie os getters e setters para PaginaWikipedia e CategoriaWikipedia. O código completo está no repositório do Github.
O que cada classe faz:
- PaginaWikipedia: encapsula os atributos de cada artigo do XML.
- CategoriaWikipedia: encapsula as categorias que vão ser extraídas das páginas através de expressões regulares.
- DAOPaginaWikipedia: contém os métodos de acesso aos dados para a PaginaWikipedia.
- DAOCategoriaWikipedia: o mesmo para a CategoriaWikipedia.
- WikipediaSAXParserToJDBC: é responsável pela análise do XML e extração dos elementos que precisamos para criar nossa base de dados.
- CategorizadorCategoria: utiliza expressões regulares para recuperar as categorias de cada página.
- pom.xml: arquivo do Maven, com as bibliotecas e demais configurações.
public class PaginaWikipedia {
private Long id;
private String title;
private Date timeStamp;
private String userName;
private String text;
private String model;
private String format;
private String comment;
}
public class CategoriaWikipedia {
private Long id;
private String descricao;
public CategoriaWikipedia(String descricao) {
this.descricao = descricao;
}
}
package net.marcoreis.wikipedia;
import java.sql.Connection;
import java.sql.Date;
import java.sql.DriverManager;
import java.sql.PreparedStatement;
import java.sql.ResultSet;
import java.sql.SQLException;
import java.sql.Timestamp;
import org.apache.log4j.Logger;
public class DAOPaginaWikipedia {
private static Logger logger = Logger.getLogger(DAOPaginaWikipedia.class);
private Connection conexao;
private String pwd = "";
private String user = "root";
private String url = "jdbc:mysql://localhost:3306/db_wikipedia";
private String driver = "com.mysql.jdbc.Driver";
public DAOPaginaWikipedia() {
try {
Class.forName(driver);
conexao = DriverManager.getConnection(url, user, pwd);
} catch (Exception e) {
throw new RuntimeException(e);
}
}
public void inserir(PaginaWikipedia pagina) {
try {
String sql = "insert into PaginaWikipedia (id, title, timestamp, username, text, model, format, comment) values (?,?,?,?,?,?,?,?)";
PreparedStatement pstmt = conexao.prepareStatement(sql);
pstmt.setLong(1, pagina.getId());
pstmt.setString(2, pagina.getTitle());
Date data = new Date(pagina.getTimeStamp().getTime());
pstmt.setTimestamp(3, new Timestamp(data.getTime()));
pstmt.setString(4, pagina.getUserName());
pstmt.setString(5, pagina.getText());
pstmt.setString(6, pagina.getModel());
pstmt.setString(7, pagina.getFormat());
pstmt.setString(8, pagina.getComment());
int qtd = pstmt.executeUpdate();
if (qtd != 1) {
logger.error("Registro nao incluido -> " + pagina.getId());
}
pstmt.close();
} catch (Exception e) {
logger.error(e);
}
}
public ResultSet findAll() {
try {
String sql = "select id, text from PaginaWikipedia";
PreparedStatement pstmt = conexao.prepareStatement(sql,
ResultSet.TYPE_FORWARD_ONLY, ResultSet.CONCUR_READ_ONLY);
pstmt.setFetchSize(Integer.MIN_VALUE);
ResultSet rs = pstmt.executeQuery();
return rs;
} catch (Exception e) {
throw new RuntimeException(e);
}
}
public void fechar() throws SQLException {
conexao.close();
}
}
package net.marcoreis.wikipedia;
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.PreparedStatement;
import java.sql.SQLException;
import org.apache.log4j.Logger;
public class DAOCategoriaWikipedia {
private static Logger logger = Logger
.getLogger(DAOCategoriaWikipedia.class);
private Connection conexao;
private String pwd = "";
private String user = "root";
private String url = "jdbc:mysql://localhost:3306/db_wikipedia";
private String driver = "com.mysql.jdbc.Driver";
public DAOCategoriaWikipedia() {
try {
Class.forName(driver);
conexao = DriverManager.getConnection(url, user, pwd);
} catch (Exception e) {
throw new RuntimeException(e);
}
}
public void inserir(CategoriaWikipedia categoria) {
try {
String sql = "insert into Categoria (descricao) values (?)";
PreparedStatement pstmt = conexao.prepareStatement(sql);
pstmt.setString(1, categoria.getDescricao());
pstmt.executeUpdate();
pstmt.close();
} catch (Exception e) {
logger.error(e);
}
}
public void fechar() {
try {
conexao.close();
} catch (SQLException e) {
throw new RuntimeException(e);
}
}
}
public class WikipediaSAXParserToJDBC extends DefaultHandler {
private static String nomeArquivo = System.getProperty("user.home")
+ "/dados/ptwiki-20130817-pages-articles-multistream.xml";
private static Logger logger = Logger
.getLogger(WikipediaSAXParserToJDBC.class);
private PaginaWikipedia pagina;
private StringBuilder content = new StringBuilder();
//Formato da data no dump da Wikipedia
private SimpleDateFormat sdf = new SimpleDateFormat(
"yyyy-MM-dd'T'HH:mm:ss'Z'");
private int paginasIndexadas;
private DAOPaginaWikipedia dao = new DAOPaginaWikipedia();
public void startElement(String uri, String localName, String qName,
Attributes attributes) throws SAXException {
if (qName.equals("page")) {
pagina = new PaginaWikipedia();
content.setLength(0);
} else if (qName.equals("title")) {
content.setLength(0);
} else if (qName.equals("timestamp")) {
content.setLength(0);
} else if (qName.equals("username")) {
content.setLength(0);
} else if (qName.equals("text")) {
content.setLength(0);
} else if (qName.equals("model")) {
content.setLength(0);
} else if (qName.equals("format")) {
content.setLength(0);
} else if (qName.equals("comment")) {
content.setLength(0);
} else if (qName.equals("id")) {
content.setLength(0);
}
}
public void characters(char[] ch, int start, int length)
throws SAXException {
content.append(String.copyValueOf(ch, start, length).trim());
}
public void endElement(String uri, String localName, String qName)
throws SAXException {
if (qName.equals("page")) {
dao.inserir(pagina);
paginasIndexadas++;
// pagina = null;
logAndamento();
} else if (qName.equals("title")) {
pagina.setTitle(content.toString());
} else if (qName.equals("timestamp")) {
try {
Date timestamp = sdf.parse(content.toString());
pagina.setTimeStamp(timestamp);
} catch (ParseException e) {
logger.error(e);
}
} else if (qName.equals("username")) {
pagina.setUserName(content.toString());
} else if (qName.equals("text")) {
pagina.setText(content.toString());
} else if (qName.equals("model")) {
pagina.setModel(content.toString());
} else if (qName.equals("format")) {
pagina.setFormat(content.toString());
} else if (qName.equals("comment")) {
pagina.setComment(content.toString());
} else if (qName.equals("id")) {
if (pagina.getId() == null)
pagina.setId(new Long(content.toString()));
}
}
private void logAndamento() {
if (paginasIndexadas % 10000 == 0) {
logger.info("Parcial: " + paginasIndexadas);
}
}
public static void main(String[] args) {
new WikipediaSAXParserToJDBC().parse();
}
public void parse() {
try {
SAXParserFactory factory = SAXParserFactory.newInstance();
factory.setNamespaceAware(true);
SAXParser parser = factory.newSAXParser();
parser.parse(new File(nomeArquivo), this);
} catch (Exception e) {
logger.error(e);
}
}
}
package net.marcoreis.wikipedia;
import java.sql.ResultSet;
import java.util.Collection;
import java.util.HashSet;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
import org.apache.log4j.Logger;
public class CategorizadorWikipedia {
private static Logger logger = Logger
.getLogger(CategorizadorWikipedia.class);
private Pattern pattern = Pattern.compile("\[\[Categoria\:(.*?)\]\]");
private DAOCategoriaWikipedia daoCategoria = new DAOCategoriaWikipedia();
private DAOPaginaWikipedia daoPagina = new DAOPaginaWikipedia();
private Collection
public void criarCategorias() {
try {
int quantidadePaginasAnalisadas = 0;
ResultSet rs = daoPagina.findAll();
while (rs.next()) {
String texto = rs.getString("text");
Matcher matcher = pattern.matcher(texto);
//
while (matcher.find()) {
String categoria = matcher.group(1);
//
if (categoria.contains("|")) {
String subCategorias[] = categoria.split("\|");
for (String subCategoria : subCategorias) {
if (subCategoria.length() > 0)
categorias.add(subCategoria.trim());
}
} else {
categorias.add(categoria.trim());
}
}
quantidadePaginasAnalisadas++;
}
logger.info("Quantidade de paginas analisados: "
+ quantidadePaginasAnalisadas);
rs.close();
daoPagina.fechar();
} catch (Exception e) {
logger.error(e);
}
}
public static void main(String[] args) {
CategorizadorWikipedia c = new CategorizadorWikipedia();
c.criarCategorias();
c.inserirCategorias();
}
private void inserirCategorias() {
int quantidadeCategoriasCriadas = 0;
for (String categoria : categorias) {
daoCategoria.inserir(new CategoriaWikipedia(categoria));
quantidadeCategoriasCriadas++;
}
logger.info("Quantidade de categorias criadas: "
+ quantidadeCategoriasCriadas);
daoCategoria.fechar();
}
}
pom.xml
6. Processamento de texto
Esta é uma aplicação baseada em processamento de grandes quantidades de texto e que utiliza muitos objetos do tipo String. As Strings são classes fundamentais em Java, tanto que têm implementação levemente diferente das demais, pois tem seus próprios literais e operadores. Em uma aplicação típica, boa parte da memória e do processamento é usado com Strings, por isso é importante entender seu funcionamento.
A classe java.lang.String tem algumas características importantes que devem ser levadas em consideração.
- String é uma implementação imutável de CharSequence. Cada objeto String é uma cadeira de caracteres única.
- String é “thread safe”, o que gera um pouco mais de overhead.
- String é uma classe final, não permite subclasses.
Uma curiosidade: se o programador criar uma String com valor “marco” e depois criar novamente outra String com o mesmo valor, serão dois objetos em memória, mesmo que tenham a sequência de caracteres “marco”. Se isso acontecer em uma escala de milhões de objetos, pode haver impacto na performance da aplicação. Por isso, funcionalidades que criam muitas Strings devem ser tratadas com cuidado.
StringBuilder
Ao contrário da String, StringBuilder é uma implementação mutável de CharSequence. Ela contém um array de caracteres que pode ser redimensionado através de métodos como append(). Após adicionar o conteúdo, podemos usar o toString() para construir uma String baseada nos valores acumulados. Essa foi a classe escolhida para ser utilizada em WikipediaSAXParserToJDBC porque é mais eficiente para esse tipo de aplicação, onde há muita concatenação de Strings. No nosso exemplo, há uma reutilização do buffer, ao invés da criação de novos objetos em memória.
Para termos noção da diferença na utilização das duas abordagens foi criada a classe WikipediaSAXParserToJDBCComString, que faz a mesma coisa que WikipediaSAXParserToJDBC, mas utiliza String no lugar de StringBuilder. Seguem logo abaixo alguns testes realizados com as duas classes. Para repetir os tester você deve fazer um drop/create table na tabela PaginaWikipedia.
Testes
Para incluir 10000 registros com WikipediaSAXParserToJDBCComString:
20:14:41,455 INFO WikipediaSAXParserToJDBCComString:102 - Inicio
20:18:01,276 INFO WikipediaSAXParserToJDBCComString:92 - Parcial: 10000
Para incluir os mesmos 10000 registros com WikipediaSAXParserToJDBC:
20:18:42,847 INFO WikipediaSAXParserToJDBC:102 - Inicio
20:20:43,576 INFO WikipediaSAXParserToJDBC:92 - Parcial: 10000
A diferença de tempo é sensível entre as duas classes. Se utilizarmos String para o processamento a execução leva 3:20 minutos, enquanto que com StringBuilder leva 2:01 minutos. A diferença também pode ser visualizada através do profiler do VisualVM.
Na figura 1 o método characters, onde é feita a concatenação do conteúdo de cada elemento XML, é o segundo na lista de consumo de tempo da CPU quando utiliza String, ocupando por 42% do tempo de processamento, isso considerando a inclusão de 10000 registros.
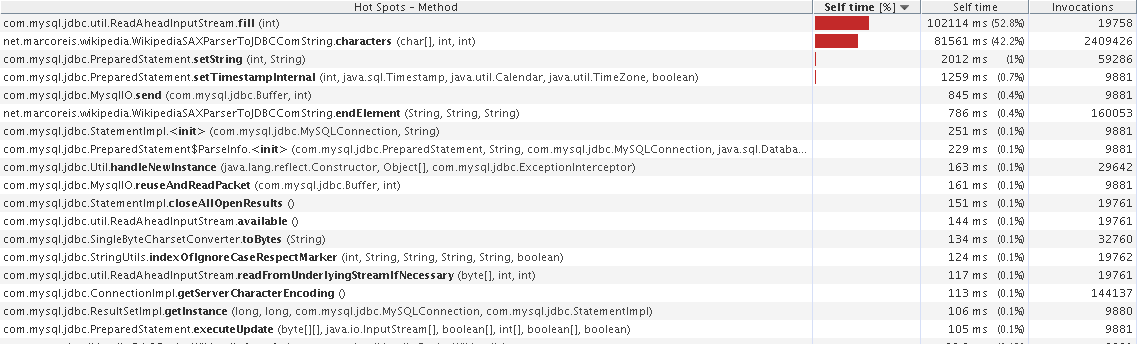
Na figura 2 o método characters aparece apenas na sexta posição, ocupando a CPU por 683ms quando se utiliza StringBuilder, também considerando a inclusão de 10000 registros.

7. Considerações sobre performance
Para inclusão dos registros no banco de dados há muita atividade no disco. Em contrapartida, o processador fica bastante tranquilo. Conclusão: incluir registros no banco de dados é bastante custoso para o disco.
Com o processamento das expressões regulares praticamente não há atividade de disco, em compensação o processamento é bastante elevado. Concluímos assim que o processamento de expressões regulares é muito custoso para o processador, mas não para o disco.
8. Referência
Expressões Regulares
Java Regex Tutorial
Java Regular Expression Tutorial with Examples
Text Processing with Java
Working with Text