O Apache Hadoop chegou na versão 3 trazendo novidades que eram esperadas há muito tempo. É claro que a instalação e configuração do ecossistema do Hadoop pode ser complicada, por isso, neste artigo vamos criar uma plataforma para análise de dados com Hadoop 3, Hive 3 e Spark 2.4.
E não é necessário ter um grande datacenter, ou seja, é possível em máquinas mais simples como notebooks e desktops para estudo, provas de conceito ou demonstração. Na verdade, é possível rodar um cluster completo em uma única máquina (com Linux), como vamos ver a seguir.
A análise de dados é uma atividade cada vez mais importante para as empresas e o Hadoop se tornou sinônimo de software para big data. Neste sentido, o ecossistema do Hadoop tem evoluído com a inclusão de novas ferramentas para análises, sendo que a primeira dessas ferramentas foi o Hive, uma ferramenta de data warehouse.
Em seguida, o Spark surgiu como uma alternativa mais performática para processamento in-memory, no lugar do processamento em batch do Hadoop. Hoje, as 3 ferramentas (Hadoop, Hive e Spark) estão integradas para entregar uma solução bastante satisfatória para análise de dados.
Uma observação é que este artigo não mostrará as técnicas, teorias ou arquiteturas usadas na área de big data, mas apenas a instalação e configuração do ambiente, o que já é bastante trabalho, considerando que o Hadoop 3 e Hive 3 foram lançados recentemente e ainda não estão completamente integrados ao Spark 2.4.
Talvez esta seja a grande vantagem das distribuições Hadoop como Cloudera e HortonWorks, pois elas trazem as ferramentas de big data integradas, sem essa dor de cabeça que é a compatibilidade das bibliotecas. Por outro lado, essas distribuições consomem mais recursos, o que pode ser um problema se você tiver hardware limitado e quiser apenas fazer experimentos.
Com isso, o pré-requisito para a instalação da nossa plataforma é uma máquina com pelo menos processador i5, 8 GB de memória, 200 GB de disco, Linux, JDK 8, acesso à internet e MySQL (ou outro SGBDR). Com poucas adaptações é possível adicionar novas máquinas e até colocar o ambiente em produção, mas começamos pela parte mais simples, a preparação do SO. Uma sugestão é usar uma VM, ou várias, de acordo com o hardware disponível.
Preparação do sistema operacional
O primeiro passo é a criação do usuário dataengineer no Linux. Vamos usar o usuário dataengineer, mas precisamos do root para tarefas administrativas. O grupo supergroup é usado no Hadoop para tarefas administrativas.
sudo useradd -m dataengineer -s /bin/bash
sudo passwd dataengineer
sudo groupadd supergroup
sudo usermod -a -G supergroup dataengineer
sudo usermod -a -G sudo dataengineerDevem ser criados 3 diretórios, um para cada ferramenta:
sudo mkdir /opt/hadoop/
sudo mkdir /opt/hive/
sudo mkdir /opt/spark/O download das ferramentas pode ser feito desta forma:
wget http://ftp.unicamp.br/pub/apache/hadoop/common/hadoop-3.1.1/hadoop-3.1.1.tar.gz
wget https://archive.apache.org/dist/hive/hive-3.1.1/apache-hive-3.1.1-bin.tar.gz
wget wget https://archive.apache.org/dist/spark/spark-2.4.0/spark-2.4.0-bin-without-hadoop.tgzInstalação das ferramentas
A instalação das ferramentas não têm muita dificuldade, apenas descompacte:
sudo tar -xvzf hadoop-3.1.1.tar.gz --directory=/opt/hadoop/ --strip 1
sudo tar -xvzf apache-hive-3.1.1-bin.tar.gz --directory=/opt/hive/ --strip 1
sudo tar -xvzf spark-2.4.0-bin-without-hadoop.tgz --directory=/opt/spark/ --strip 1Geração das chaves
O Hadoop precisa executar comandos como root, por isso precisamos criar as chaves públicas e privadas:
ssh-keygen
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keysPara verificar se está funcionando, o ssh tem de se conectar sem pedir a senha. Esse passo deve ser repetido em todas as máquinas do cluster.
ssh headnode01Discos de dados
Cada máquina do ambiente pode usar um ou vários discos para armazenamento dos dados. O padrão é /data/1 e, se houver mais discos, adicione-os seguindo uma sequência numérica, por exemplo /data/2.
Certifique-se de que tem espaço no disco para os experimentos. A sugestão é usar uma partição separada exclusivamente para os dados, ou seja, não use a partição do sistema operacional, o famoso /, porque o Hadoop pode consumir o disco todo e a máquina simplesmente vai parar. De toda forma, é possível adicionar mais discos depois.
sudo mkdir -p /data/1/
sudo chown dataengineer:dataengineer /data/1Arquivos de configuração do Hadoop
As variáveis de ambiente da plataforma devem ser configuradas no arquivo /etc/profile, que serão utilizados pelo Hadoop/Hive/Spark. São parâmetros como usuário, diretório home e os diretório dos arquivos de configuração. Em ambiente maior pode ser melhor usar um diretório centralizado para as configurações das diversas máquinas.
Outra variável importante é a HIVE_AUX_JARS_PATH, que aponta para bibliotecas auxiliares usadas no Hive. O Hive vai usar o Spark para processamento, por isso precisamos usar esses 3 arquivos indicados, o spark-core_2.11-2.4.0.jar, o scala-library-2.11.12.jar e o spark-network-common_2.11-2.4.0.jar.
export HDFS_NAMENODE_USER=root
export HDFS_DATANODE_USER=root
export HDFS_SECONDARYNAMENODE_USER=root
#
export HADOOP_HOME=/opt/hadoop
export HADOOP_CONF_DIR=/opt/hadoop/etc/hadoop
#
export YARN_HOME=$HADOOP_HOME
export YARN_RESOURCEMANAGER_USER=root
export YARN_NODEMANAGER_USER=root
#
export HIVE_AUX_JARS_PATH=/opt/spark/jars/spark-core_2.11-2.4.0.jar,/opt/spark/jars/scala-library-2.11.12.jar,/opt/spark/jars/spark-network-common_2.11-2.4.0.jar
#
export SPARK_HOME=/opt/spark
export SPARK_CONF_DIR=/opt/spark/conf
export SPARK_MASTER_HOST=headnode01
#
export JAVA_HOME=SEU_DIRETORIO_JAVA_HOME
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:/opt/hive/bin:/opt/spark/binDepois de salvar o arquivo, as variáveis serão carregadas no próximo reboot da máquina. Para forçar o carregamento imediato usamos o comando source como root:
su -
source /etc/profileOs arquivos de configuração não mudaram (muito) no Hadoop 3. A configuração básica continua sendo feito com o core-site.xml, hdfs-site.xml, yarn-site.xml e hadoop-env.sh. Vamos ao primeiro deles:
Arquivo /opt/hadoop/etc/hadoop/core-site.xml
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>fs.default.name</name>
<value>hdfs://headnode01:8020/</value>
</property>
<property>
<name>hadoop.proxyuser.root.groups</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.root.hosts</name>
<value>*</value>
</property>
</configuration>Arquivo /opt/hadoop/etc/hadoop/hdfs-site.xml
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>dfs.datanode.data.dir</name>
<value>/data/1/dn</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>/data/1/nn</value>
</property>
<property>
<name>dfs.namenode.http-address</name>
<value>headnode01:50070</value>
</property>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
</configuration>Arquivo /opt/hadoop/etc/hadoop/workers
O arquivo workers contém a lista de máquinas que fazem parte do cluster, ou seja, apenas escreva headnode01.
Arquivo /opt/hadoop/etc/hadoop/yarn-site.xml
A configuração de memória pode ser meio complicada no início, por isso a Cloudera disponibiliza uma planilha de cortesia que ajuda bastante neste cálculo.
Como ponto de partida, vamos usar a configuração abaixo, para uma máquina de 8 GB e 8 processadores:
<?xml version="1.0" encoding="UTF-8" standalone="no"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.scheduler.maximum-allocation-mb</name>
<value>7168</value>
</property>
<property>
<name>yarn.nodemanager.resource.memory-mb</name>
<value>7168</value>
</property>
<property>
<name>yarn.scheduler.maximum-allocation-vcores</name>
<value>7</value>
</property>
<property>
<name>yarn.nodemanager.resource.cpu-vcores</name>
<value>7</value>
</property>
</configuration>Estes são os principais parâmetros vistos acima:
yarn.scheduler.maximum-allocation-mb: quantidade de memória disponível para um container nesta máquina, que não pode ser maior que oyarn.scheduler.maximum-allocation-mb;yarn.nodemanager.resource.memory-mb: quantidade de memória disponível na máquina para ser usada pelo Hadoop, subtraindo aí 1 GB para o sistema operacional;yarn.scheduler.maximum-allocation-vcores: quantidade máxima de vcores disponíveis para um container, que não pode ser maior que oyarn.nodemanager.resource.cpu-vcores;yarn.nodemanager.resource.cpu-vcores: quantidade de vcores (CPUs virtuais) disponíveis, menos uma para o SO.
Arquivo /opt/hadoop/etc/hadoop/hadoop-env.sh
Apenas preencha essa linha o JAVA_HOME:
export JAVA_HOME=SEU_DIRETORIO_JAVA_HOMEFormatação do sistema de arquivos (HDFS)
Antes do primeiro uso, o sistema de arquivos (HDFS) deve ser formatado:
hdfs namenode -formatInicialização dos serviços do Hadoop
O script de inicialização do Hadoop 3 continua o mesmo. Você pode inicializar o HDFS e o YARN separadamente, ou inicializar todos de uma só vez. Isso é interessante porque nem sempre usamos o YARN, por exemplo se estiver usando o cluster do Spark. Então, para inicializar um serviço de cada vez:
start-dfs.sh
start-yarn.shPara inicializar todos os serviços:
start-all.shSe tudo estiver correto teremos ao menos 1 live datanode. O comando para verificar o estado do HDFS é esse:
hdfs dfsadmin -reportO resultado para um sistema saudável seria parecido com esse, no qual temos um disco de 275 GB. Veja os valores:
Configured Capacity: 295155871744 (274.89 GB)
Present Capacity: 254285553664 (236.82 GB)
DFS Remaining: 249311576064 (232.19 GB)
DFS Used: 4973977600 (4.63 GB)
DFS Used%: 1.96%
Replicated Blocks:
Under replicated blocks: 0
Blocks with corrupt replicas: 0
Missing blocks: 0
Missing blocks (with replication factor 1): 0
Pending deletion blocks: 0
Erasure Coded Block Groups:
Low redundancy block groups: 0
Block groups with corrupt internal blocks: 0
Missing block groups: 0
Pending deletion blocks: 0
-------------------------------------------------
Live datanodes (1):
Name: 192.168.122.1:9866 (headnode01)
Hostname: headnode01
Decommission Status : Normal
Configured Capacity: 295155871744 (274.89 GB)
DFS Used: 4973977600 (4.63 GB)
Non DFS Used: 25853542400 (24.08 GB)
DFS Remaining: 249311576064 (232.19 GB)
DFS Used%: 1.69%
DFS Remaining%: 84.47%
Configured Cache Capacity: 0 (0 B)
Cache Used: 0 (0 B)
Cache Remaining: 0 (0 B)
Cache Used%: 100.00%
Cache Remaining%: 0.00%
Xceivers: 1
Last contact: Sat Jan 12 18:49:30 BRST 2019
Last Block Report: Sat Jan 12 18:46:19 BRST 2019
Num of Blocks: 65O Hadoop disponibiliza interfaces Web para cada um dos serviços. O serviço do YARN está disponível na URL http://headnode01:8088, como na figura abaixo:

A interface Web do HDFS está na URL e http://headnode01:50070, que pode ser vista na figura abaixo:

Em caso de erro, a melhor forma de investigar e consertar é pela análise dos logs, uma das informações mais importantes para a manutenção do Hadoop. Os logs estão disponíveis em /opt/hadoop/logs. O próximo passo é configurar o Hive.
Apache Hive
O Apache Hive é um data warehouse para o Hadoop e permite a execução de comandos SQL. A sintaxe dos comandos do HiveQL, ou Hive Query Language, está disponível aqui. Esta técnica de integração entre Hadoop e SQL, conhecida como SQL-on-Hadoop, tem se popularizado, como pode ser visto na seção Ferramentas de SQL-on-Hadoop.
Mais que isso, o Hive permite escrever o ETL (extract, transform and load) para os dados corporativos. E como dito antes, temos a integração do Hive com as ferramentas de relatório e BI tradicionais.
Outro ponto interessante é que há diversos formatos de arquivo suportados pelo Hive, como o Parquet e o ORC, que oferecem melhor performance ou compactação. Neste sentido, o Hive é uma ferramenta útil para converão de formatos, ou seja, podemos trabalhar com arquivos XML e JSON, formatos comuns para transferência de dados.
A configuração do Hive é um pouco mais simples, com dois passos. Inicialmente copiamos o driver do MySQL.
wget http://central.maven.org/maven2/mysql/mysql-connector-java/5.1.28/mysql-connector-java-5.1.28.jar
sudo cp mysql-connector-java-5.1.28.jar /opt/hive/libEm seguida configuramos o banco para a MetaStore, que é o repositório de metadados do Hive. Neste ponto pode-se optar pelos principais bancos do mercado, como Oracle ou Postgre. O importante é não usar o banco padrão, que seria o Derby, porque não seria possível expandir a instalação para um cluster, uma vez que o Derby é um banco local. Neste caso, o arquivo de configuração é hive-site.xml, que está abaixo.
Arquivo /opt/hive/conf/hive-site.xml
<?xml version="1.0" encoding="UTF-8" standalone="no"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://headnode01/metastore?createDatabaseIfNotExist=true</value>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
</property>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>root</value>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>root</value>
</property>
<property>
<name>hive.metastore.warehouse.dir</name>
<value>/user/hive/warehouse</value>
</property>
<property>
<name>hive.cli.print.header</name>
<value>true</value>
</property>
</configuration>Para criar a MetaStore do Hive só precisamos executar uma vez o comando abaixo, que irá criar o esquema de banco de dados e as tabelas.
schematool -dbType mysql -initSchema --verboseA MetaStore é um serviço do Hive que precisa ser inicializado com o comando:
hive --service metastore &Para verificar as informações do serviço MetaStore o comando é:
schematool -dbType mysql -info --verboseO resultado deve ser o abaixo, ou seja, tanto a versão do Hive quanto da MetaStore é 3.1.0.
Metastore connection URL: jdbc:mysql://headnode01/metastore?createDatabaseIfNotExist=true
Metastore Connection Driver : com.mysql.jdbc.Driver
Metastore connection User: root
Hive distribution version: 3.1.0
Metastore schema version: 3.1.0HiveServer2 (HS2)
O Hive tem um serviço para clientes remotos chamado de HiverServer2 que permite a conexão de ferramentas externas como o Squirrel, JasperSoft, Power BI, Qlik Sense, Tableau ou o Beeline, sendo que este último será usado para executar as nossas consultas no Hive na seção Clientes Hive.
hive --service hiveserver2Depois da inicialização, a interface Web do HS2 ficará disponível na URL http://headnode01:10002/, na qual podem ser conferidas as sessões ativas, as últimas consultas, as versões, logs, métricas e configurações, como pode ser visto na figura abaixo:

Apache Spark
O Apache Spark é um sistema para computação distribuída de alto desempenho que será usado neste artigo como mecanismo de execução para o Hive. Por padrão, o Hive usa MapReduce para execução das consultas, mas este modelo tem performance bastante ruim e não é recomandado.
O Spark é um mecanismo para processamento de dados de propósito geral e pode ser usada em diversas situações. Ele é a base para outras soluções, como machine learning, grafos, SQL, processamento em tempo real, integração de dados e análise interativa. Em termos de linguagens de programação, ele suporta Java, Python, Scala e R.
Muito mais do que apenas um mecanismo de execução, o Spark é uma das ferramentas mais importantes para os sistemas de big data. Contudo, não é objetivo deste texto falar sobre isso. Ainda assim, sou grande fã do Spark.
A primeira configuração é a integração entre o Spark e o Hive, que é feita copiando o hive-site.xml. Este arquivo contém as configurações do Hive e da sua MetaStore. Uma solução um pouco melhor do que apenas copiar o arquivo é usar um link simbólico no Linux.
sudo ln -s /opt/hive/conf/hive-site.xml /opt/spark/conf/hive-site.xmlA outra configuração é copiar o driver do MySQL para o Spark:
sudo cp mysql-connector-java-5.1.28.jar /opt/spark/jarsArquivo /opt/spark/conf/slaves
O arquivo slaves contém a lista de workers do cluster Spark, ou seja, quais os servidores que vão executar o processamento. No nosso caso temos apenas o headnode01.
Arquivo /opt/spark/conf/spark-env.sh
O spark-env.sh tem as variáveis de ambiente do Spark, como o classpath, o servidor master e o JAVA_HOME.
export SPARK_DIST_CLASSPATH=$(/opt/hadoop/bin/hadoop classpath)
export SPARK_MASTER_HOST=headnode01
export JAVA_HOME=SEU_DIRETORIO_JAVA_HOMEArquivo /opt/spark/conf/spark-defaults.conf
O spark-defaults.conf guarda configurações do Spark como memória, diretório de bibliotecas auxiliares e número de processadores usados. Mais detalhes neste link.
No nosso arquivo de configuração vamos definir que os arquivos de staging fiquem gravados no disco depois da execução e não serão excluídos, que seria o comportamento padrão. Isso garante a economia de alguns segundos durante a inicialização do ambiente.
spark.yarn.preserve.staging.files truePara inicializar os serviços do Spark os comando são:
/opt/spark/sbin/start-master.sh
/opt/spark/sbin/start-slaves.shOpcionalmente, pode-se usar o comando start-all.sh:
/opt/spark/sbin/start-all.shO diretório de logs do Spark está disponível, por padrão, em /opt/spark/logs/ e a interface web pode ser conferida nas URLs http://headnode01:8080/ para o master e http://headnode01:8081/ para o slave.
Com isso, concluímos a instalação da nossa plataforma para análise de dados. A seguir vamos importar os dados e avaliar se tudo está funcionando.
Opcional: remover bibliotecas incompatíveis
As incompatibilidades do Hive/Spark acontecem porque a versão das bibliotecas em cada ferramenta é diferente. Este é o caso do formato ORC, um tipo de arquivo de alta compactação que pode ser usado para armazenar os dados no Hive.
No Hive, o ORC está na versão 1.5.1, enquanto que no Spark está na versão 1.5.2. Por isso são incompatíveis. Para poder usar o formato ORC no Hive temos de excluir algumas bibliotecas no Spark. São elas:
rm /opt/spark/jars/orc-core-1.5.2-nohive.jar
rm /opt/spark/jars/orc-mapreduce-1.5.2-nohive.jar
rm /opt/spark/jars/orc-shims-1.5.2.jarBase de dados
A base de dados usada nas análises para avaliar se a plataforma está funcionando está disponível no Kaggle. Este dataset contém informações de um e-commerce, com seus clientes, vendedores, compras e produtos. O dataset é pequeno, sendo usado apenas para verificar se os componentes da plataforma estão integrados.
Futuramente, vamos usar datasets com bilhões de registros para testar a performance da plataforma. Por ora, vamos trabalhar com apenas um dos arquivos do e-commerce, o olist_order_items_dataset.csv.
O sistema de arquivos padrão do Hadoop é o HDFS, que é baseado em blocos de tamanho fixo, geralmente de 64 MB ou 128 MB. Existem outras opções, como sistemas baseados em objetos, como o S3, o OpenStack Swift e o novíssimo Hadoop Ozone.
Os comandos do HDFS são parecidos com os do Linux, como mkdir e du. Assim, o código a seguir cria o diretório no HDFS, copia o arquivo e verifica o espaço utilizado no disco.
hdfs dfs -mkdir -p /user/dataengineer/data/ecommerce/pedido_item
hdfs dfs -put olist_order_items_dataset.csv /user/dataengineer/data/ecommerce/pedido_item/
hdfs dfs -du -h /user/dataengineer/data/ecommerce/A estrutura deste arquivo pode ser vista no bloco de código a seguir:
"order_id","order_item_id","product_id","seller_id","shipping_limit_date","price","freight_value"
"00010242fe8c5a6d1ba2dd792cb16214",1,"4244733e06e7ecb4970a6e2683c13e61","48436dade18ac8b2bce089ec2a041202",2017-09-19 09:45:35,58.90,13.29A partir de agora vamos usar o usuário dataengineer para criar as estruturas de dados e as consultas no Hive. O ideal é ter dois terminais abertos, um com o usuário dataengineer para executar as análises com o Hive e outro terminal com o usuário root para tarefas administrativas.
su - dataengineerClientes Hive
O Hive tem dois clientes nativos, o Hive CLI e o Beeline. Basicamente, ambos funcionam da mesma forma e não apresentam grande diferença para nossos exemplos. Contudo, o Hive CLI tem algumas limitações com conexões remotas. Por isso, vamos optar por usar o Beeline, que é o cliente Hive mais recente. Mas é possível usar também o Squirrel ou qualquer outro cliente JDBC.
O Beeline se conecta com o HiveServer2 que, por padrão, está disponível na porta 10000. Assim, o comando para se conectar com o Beeline está a seguir. Lembrando que devemos executar o comando com o usuário dataengineer:
beeline -u jdbc:hive2://headnode01:10000/ -n dataengineerComo resultado, o Beeline vai abrir uma linha de comando para o usuário entrar com os comandos no Hive, como visto na listagem abaixo:
Connecting to jdbc:hive2://headnode01:10000
Connected to: Apache Hive (version 3.1.1)
Driver: Hive JDBC (version 3.1.1)
Transaction isolation: TRANSACTION_REPEATABLE_READ
Beeline version 3.1.1 by Apache Hive
0: jdbc:hive2://headnode01:10000>O primeiro comando Hive será a criação do esquema de dados, que vai englobar as tabelas. O comando é:
create schema datalake;Para criar a tabela pedido_item o comando no Hive está abaixo.
A tabela usada nos exemplos é a pedido_item. Esta será uma tabela externa (EXTERNAL TABLE), uma estrutura temporária que aponta para o arquivo olist_order_items_dataset.csv. A tabela definitiva será criada mais para frente.
Veja que o Hive funciona como um interpretador entre o SQL e o arquivo CSV, mais precisamente com o diretório pedido_item e todos os arquivos que estiverem lá dentro.
CREATE EXTERNAL TABLE datalake.pedido_item
(
id_pedido string,
id_item_pedido string,
id_produto string,
id_vendedor string,
data_envio string,
valor_item double,
valor_frete double
)
ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.OpenCSVSerde'
WITH SERDEPROPERTIES (
"separatorChar" = ",",
"quoteChar" = "\"",
"escapeChar" = "\\"
)
STORED AS TextFile
LOCATION '/user/dataengineer/data/ecommerce/pedido_item'
TBLPROPERTIES("skip.header.line.count" = "1");O utilitário que faz a conversão entre as linhas do arquivo CSV e o Hive é o OpenCSVSerde. Esta conversão de formatos no Hive é feita por meio de uma funcionalidade chamada SerDe (Serializer/Deserializer), que suporta vários formatos incluindo Avro, ORC, RegEx, Thrift, Parquet, CSV, XML e JSON.
Um teste rápido para ver se a tabela temporária foi criada e está populada pode ser feito com SQL, desta forma:
use datalake;
show tables;
select * from pedido_item;Com isso deveria ser possível ver os registros importados do CSV. As análises de dados com SQL serão realizadas na próxima seção.
Modos de execução
O Hive é uma ferramenta de data warehouse com suporte a SQL. Sua performance foi melhorando com o tempo e, hoje, com o Spark, é possível processar bilhões de registros em um tempo bastante razoável. Mas antes de executar as consultas precisamos definir o modo de execução do Hive.
O Hive pode ser executado de várias formas, sendo que as 2 primeiras não são recomandadas (local e MapReduce). As opções de execução do Hive são:
- Local: em uma única máquina (péssima performance);
- MapReduce: transforma as consultas em programas MapReduce (péssima performance);
- Hive-on-Spark no cluster YARN: funcionalidade mais recente que tem boa performance;
- Hive-on-Spark no cluster Spark: parece com a solução anterior e também tem boa performance.
A forma de execução é definida nos arquivos de configuração, mas também podem ser feitas por meio de propriedades diretamente no console do Hive. Por exemplo, para executar as consultas no modo local, a sintaxe é set mapreduce.framework.name=local, como no exemplo:
set mapreduce.framework.name=local;
select count(1) as total from datalake.pedido_item;Para executar as consultas com MapReduce, que é o padrão do Hive, deve-se definir as variáveis mapreduce.framework.name=yarn e hive.execution.engine=mr. Assim, a consulta será convertida para um programa MapReduce. Este modo deve ser evitado, mas para usá-lo a sintaxe é:
set mapreduce.framework.name=yarn;
set hive.execution.engine=mr;
select count(1) as total from datalake.pedido_item;Hive-on-Spark é o modo de execução no qual o Hive usa o mecanismo de execução do Spark e os recursos computacionais do YARN. Neste caso, o YARN deve estar carregado. Quando a consulta é submetida uma sessão do Spark é carregada no YARN. Este é o nosso modo de execução preferencial. Para usar este modo a sintaxe é:
set hive.execution.engine=spark;
set spark.master=yarn;
select count(1) as total from datalake.pedido_item;O log do HiveServer2 deve mostrar informações como estas vistas na figura abaixo:
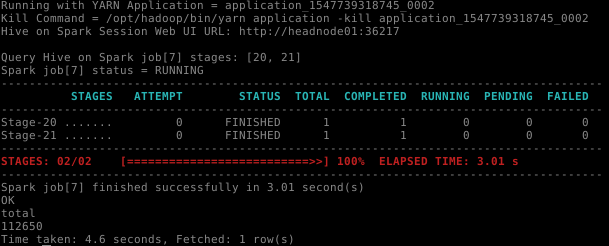
Por fim, é possível usar o Hive-on-Spark em um cluster Spark. Neste caso, o cluster do Spark deve estar carregado. A sintaxe para usá-lo é:
set hive.execution.engine=spark;
set spark.master=spark://headnode01:7077;
select count(1) as total from datalake.pedido_item;Como visto, o modo Hive-on-Spark pode ser executado no YARN ou no Spark, com performance bastante parecida nos dois casos. Com YARN tem a vantagem de usar a estrutura do Hadoop, que já está pronta. Está é a escolha da Cloudera. Para rodar o Hive-on-Spark com o cluster Spark temos de iniciar mais esse recurso, o que não chega a ser nenhum grande problema.
Formatos de arquivo
O arquivo CSV usado para criar a tabela pedido_item está em formato texto e não é adequado para consultas, porque o tempo de resposta tende a ser alto. Por isso, as tabelas externas são temporárias e não devem ser usadas para consultas, principalmente quando há muitos registros.
A solução do Hive para melhorar o tempo de resposta é a criação de tabelas em formatos otimizados. Os formatos suportados no Hive são:
- Texto: formato padrão do Hive, os arquivos estão em formato texto puro, como CSV, TSV e TXT;
- Sequence File: arquivos binários do Hadoop;
- RCFile: antigo formato binário baseado em chave-valor;
- Apache Parquet: formato adequado para consultas em larga escala, por isso é o nosso formato preferencial;
- Apache ORC (Optimized Row Columnar): formato com alto grau de compactação e performance, tem suporte a operações ACID, índices e tipos complexos;
- Apache Avro: formato usado para serialização e troca de dados, bastante popular no Hadoop.
O procedimento para criar estas tabelas otimizadas pode ser resumido assim:
- Copiar os dados para um diretório específico no HDFS;
- Criar a tabela externa apontando para o diretório no HDFS com os dados de origem;
- Criar a tabela otimizada com um dos formatos suportados (Parquet, ORC ou Avro);
- Importar os dados para a tabela otimizada.
A criação da tabela externa foi visto na seção anterior. Podemos usar aquele script e mudar apenas o formato da tabela, ou podemos fazer o create table com o comando like, que copia a estrutura da tabela original em uma nova tabela. Desta forma:
create table pedido_item_parquet like pedido_item stored as parquet;
create table pedido_item_orc like pedido_item stored as orcfile;
create table pedido_item_avro like pedido_item stored as avro;Além do formato, é importante definir a compactação da tabela. São duas vantagens: economia de espaço e de transferência de dados, que compensam o overhead causado pela compactação e descompactação. Os tipos disponíveis no Hadoop são (i) SNAPPY, (ii) GZIP, (iii) BZIP2 e (iv) LZO. O Snappy é uma compactação de uso geral, com bom equilíbrio entre performance e quantidade de compressão, por isso será a nossa escolha.
O ORC já é comprimido por padrão, mas o Avro e o Parquet não são. Por isso vamos definir a compressão no Beeline antes de inserir os dados. Opcionalmente, esses parâmetros podem ficar na configuração do Hive.
set parquet.compression=snappy;
set hive.exec.compress.output=true;
set hive.exec.compress.intermediate=true;
set avro.output.codec=snappy;Com isso estamos prontos para inserir os dados nas tabelas otimizadas. O comando para manipulação desses registros é esse:
insert into datalake.pedido_item_parquet select * from datalake.pedido_item;
insert into datalake.pedido_item_orc select * from datalake.pedido_item;
insert into datalake.pedido_item_avro select * from datalake.pedido_item;Com as tabelas populadas podemos proceder com as análises, o que demanda um pouco de SQL. Para exemplificar, aqui estão algumas consultas, que listam os 10 pedidos com maior valor:
select id_pedido, sum(valor_item) + sum(valor_frete) as valor_total from datalake.pedido_item_parquet group by id_pedido order by valor_total desc limit 10;
select id_pedido, sum(valor_item) + sum(valor_frete) as valor_total from datalake.pedido_item_orc group by id_pedido order by valor_total desc limit 10;
select id_pedido, sum(valor_item) + sum(valor_frete) as valor_total from datalake.pedido_item_avro group by id_pedido order by valor_total desc limit 10;Inserindo registros
A inclusão de registros usa SQL tradicional, um simples comando insert. Os comandos de exemplo estão a seguir:
select count(1) from pedido_item_parquet;
select count(1) from pedido_item_orc;
select count(1) from pedido_item_avro;
insert into pedido_item_parquet (id_pedido, id_item_pedido, id_produto, id_vendedor, data_envio, valor_item, valor_frete)
values ("1", "2", "3", "4", "5", 6, 7);
insert into pedido_item_orc (id_pedido, id_item_pedido, id_produto, id_vendedor, data_envio, valor_item, valor_frete)
values ("1", "2", "3", "4", "5", 6, 7);
insert into pedido_item_avro (id_pedido, id_item_pedido, id_produto, id_vendedor, data_envio, valor_item, valor_frete)
values ("1", "2", "3", "4", "5", 6, 7);
select count(1) from pedido_item_parquet;
select count(1) from pedido_item_orc;
select count(1) from pedido_item_avro;Ferramentas SQL-on-Hadoop
As ferramentas de SQL-on-Hadoop estão se popularizando porque ajudam a encurtar o caminho para implantação de soluções de big data, considerando que há mais mão de obra disponível em SQL do que em Hadoop. As principais ferramentas SQL-on-Hadoop grátis disponíveis são essas:
Conclusão
Neste artigo vimos como instalar uma plataforma para big data com as versões mais recentes do ecossistema Hadoop, que são o Hadoop 3, o Hive 3 e o Spark 2.4. A implantação de soluções de big data consiste da integração de várias ferramentas diferentes, uma tarefa que tende a ser complexa, porque são muitas configurações e parâmetros a serem definidos, em uma sequência de passos não triviais.
Foram apresentados os scripts usados para instalação e inicialização dos serviços, que são o Hadoop (YARN e HDFS), o Hive (MetaStore e HiveServer2) e o Spark, bem como uma configuração inicial.
No Hive, foram discutidos os modos de execução, formatos de arquivo e de compactação. Neste caso, a preferência é o modo de execução Hive-on-Spark no YARN e o formato de arquivo é o Parquet com a compactação Snappy para a criação das tabelas. Ainda no Hive foi mostrada uma estratégia para a criação e inserção dos dados nas tabelas.
Este ambiente pode ser usado para avaliação ou estudo dessas tecnologias e, como continuação do estudo, uma sugestão seria usar um dataset maior, como o StackOverflow.
Muito bom! Excelente! Este artigo foi de fundamental importância para que eu começasse neste mundo. Consegui construir meu próprio cluster para carregar alguns bancos e aprender sobre como funciona o Hadoop. Parabéns pela iniciativa!
Muito bom. Esclarecedor!!!!!!!!!!!!!
Muito bom, bem explicado e detalhado, gratidão!!!