Este artigo apresenta uma arquitetura de referência para soluções de big data, detalhando os componentes e suas interações, sem levar em consideração as tecnologias utilizadas para implantação deste tipo de sistema. Assim, é possível criar novos sistemas de big data a partir das descrições apresentadas. Também para documentar ou explicar os conceitos envolvidos na área de big data, que é relativamente nova.
A arquitetura de referência mostra uma visão conceitual, ou seja, de alto nível da estrutura necessária para implantar grandes sistemas em um datacenter ou em ambientes de computação em nuvem pública ou privada. O estudo completo, incluindo a implementação da arquitetura em um sistema de big data real em nuvem privada pode ser visto na minha Dissertação de Mestrado, disponível neste link.
Descrição da Arquitetura
O objetivo de um sistema de big data é tornar os dados corporativos disponíveis em um ponto centralizado, com redundância, alta disponibilidade e performance. Assim, para mostrar os diferentes aspectos deste tipo de sistema, vamos usar as visões arquiteturais descritas na sequência. Como objetivo, as características desejadas em uma arquitetura de big data são (i) reusabilidade, (ii) manutenibilidade, (iii) modularidade, (iv) performance e (v) escalabilidade.
Visão de Contexto
A Visão de Contexto apresenta a arquitetura de uma perspectiva conceitual, na qual é ilustrado o ambiente operacional do projeto e mostra o que foi incluído, e o que não foi nos limites da arquitetura, assim, de um lado estão as fontes de dados, no centro a infraestrutura para o sistema de big data e à direita os usuários do sistema.

Visão Funcional
A Visão Funcional descreve os usos, os componentes, as interfaces, as entidades externas e as principais interações entre eles, como pode ser visto na figura abaixo.
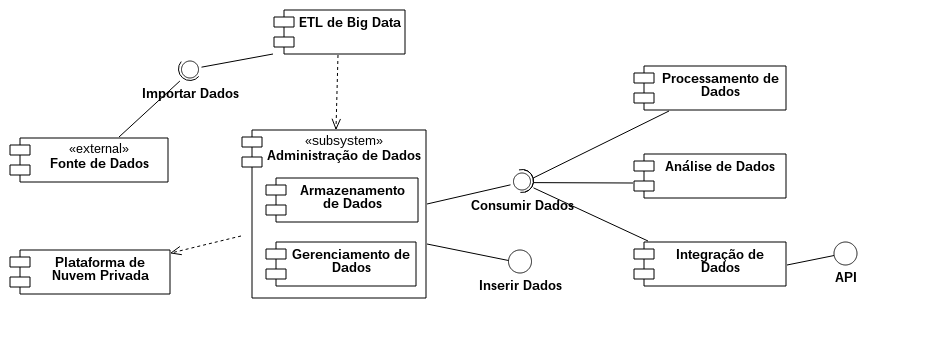
O componente de Fonte de Dados é uma entidade externa que representa, como o nome sugere, qualquer mecanismo que forneça dados corporativos, e inclui os SGBDRs, os sistemas de arquivos e os web services.
O ETL de Big Data realiza o processamento necessário para converter os dados de seu formato de origem para os formatos suportados pelo mecanismo de armazenamento de big data.
O sub-sistema de Administração de Dados é um componente lógico que envolve dois componentes. O primeiro deles é o serviço de Armazenamento de Dados, responsável por persistir os dados no sistema de arquivos distribuído. O componente de Gerenciamento de Dados é constituído pelo banco de dados NoSQL. Este sub-sistema dispõe de uma interface para que novos registros sejam inseridos sem a necessidade de passar pelo ETL de Big Data. A outra inferface permite que os demais componentes consumam diretamente os dados.
O Processamento de Dados é composto pelos mecanismos para processamento batch e tempo real, além de oferecer suporte para a implantação de programas de big data, como Hadoop e Spark, a partir de seus respectivos frameworks.
O serviço de Integração de Dados é uma funcionalidade presente nas arquiteturas de big data mais recentes. Ele oferece uma API para que entidades externas consumam os dados do sistema. A API é construída a partir de um banco NoSQL e disponibilizada por meio de web services, uma tendência na área de big data e computação em nuvem.
O último serviço é o de Análise de Dados, que combina mecanismos de consulta ad hoc, de estatística e de algoritmos de machine learning. Estas funcionalidades são usadas pelos cientistas de dados e fazem parte de uma área conhecida como big data analytics.
Componente X Ferramenta
Como visto nesta seção, a arquitetura é composta por elementos de software e de hardware. Na tabela abaixo podemos ver o mapeamento entre os componentes da arquitetura e os principais softwares disponíveis para implementação.
| Componente | Software |
|---|---|
| Plataforma de Nuvem Privada | OpenStack Pike, CentOS 7, KVM |
| ETL de Big Data | Apache Sqoop, Apache Flume, Apache Kafka, BDAT |
| Armazenamento de Dados | Apache HDFS, OpenStack Swift, Ceph |
| Gerenciamento de Dados | Apache Cassandra, Apache HBase |
| Processamento de Dados | Apache Hadoop, Apache Spark, Cloudera, Hortonworks |Integração de Dados | Spring Boot 2.0 |
| Análise de Dados | Apache Hive, Apache Spark, Apache Drill, Hue |
Visão de Implantação
A Visão de Implantação mostra o ambiente onde o sistema será instalado, bem como o software sugerido para sua execução. Os sistemas de big data criados a partir desta arquitetura são implantados em um datacenter, uma nuvem pública ou privada. Os servidores podem ser VMs ou máquinas físicas (bare metal), pois não há significativa perda de performance. Para a criação de provas de conceito é possível utilizar um único servidor desempenhando todas as funções. Neste caso, a performance não pode ser avaliada, porque os recursos computacionais são limitados. Apesar disso, é possível validar se as funcionalidades foram atendidas.
Existem quatro funcionalidades principais previstas na arquitetura, que atendem às demandas dos sistemas de big data. As funcionalidades são (i) Cluster de Big Data, no qual residem os serviços de Armazenamento e Análise de Dados. O (ii) Servidor de API engloba o serviço de Integração de Dados, enquanto o (iii) Servidor NoSQL engloba o Gerenciamento de Dados. Por fim, o (iv) Storage oferta novamente o serviço de Armazenamento de Dados, com a diferença de que nesta configuração não existe a necessidade do cluster de big data, pois é utilizada a tecnologia de object storage e data lakes, que é uma tendência no mundo do big data.
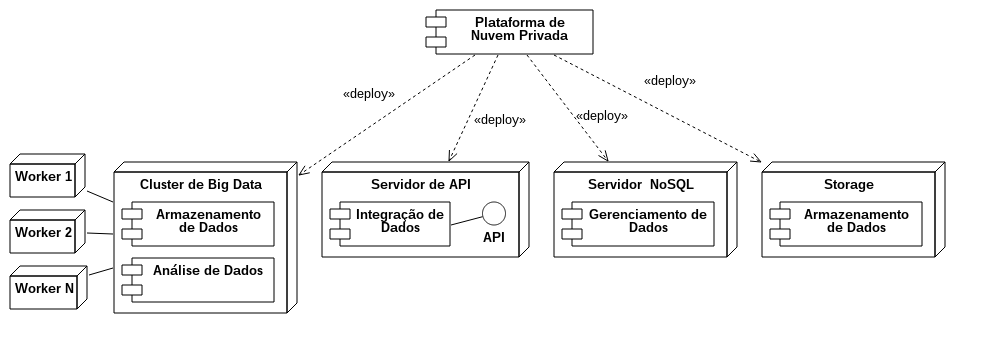
Data Lakes
Data lakes são repositórios centralizados de dados corporativos, incluindo dados estruturados, semi-estruturados e não estruturados. Esses dados estão, geralmente, em seu formato nativo e armazenados em sistemas de arquivos de baixo custo e alto desempenho, como o HDFS ou o object storage, que é a escolha desta arquitetura. A proposta do data lake é diferente de um data warehouse (DW). No DW os dados estão processados e estruturados para a consulta, e a estrutura é definida antes da ingestão no sistema, por meio de rotinas de ETL. Esta técnica é chamada de schema-on-write.
No data lake os dados estão em seu formato original, com pouca ou nenhuma transformação, e a estrutura dos dados é definida durante sua leitura, uma técnica conhecida como schema-on-read. Os usuários podem definir e redefinir rapidamente os esquemas dos dados durante o processo de leitura dos registros. Com isso, o ETL é executado a partir do próprio data lake.
A vantagem do data lake é a sua flexibilidade, que é ao mesmo tempo um problema, porque torna as análises mais complexas do que aquelas no DW. Dessa forma, os usuários do data lake devem ser altamentes especializados, como os cientistas de dados e, excepcionalmente, os desenvolvedores. Existem ainda outros riscos na adoção de data lakes, como a garantia da qualidade, a segurança, a privacidade e a governança de dados, que são questões ainda abertas.
O object storage é o principal mecanismo de armazenamento para as análises de dados, especialmente para a criação de data lakes, que será tema de outros artigos. O HDFS é outra opção para o armazenamento em sistemas de big data, entretanto, é uma solução acoplada ao próprio cluster Hadoop, o que vai contra a proposta da arquitetura de ter serviços com baixo grau de acoplamento.
Outras Arquiteturas para Big Data
Existem outras arquiteturas para sistemas de big data, sendo que uma das mais populares atualmente é a Arquitetura Lambda, que foi projetada com base nos princípios de escalabilidade, simplicidade, imutabilidade dos dados, frameworks de processamento em batch e em tempo real. A arquitetura foi criada a partir da observação dos problemas apresentados pelos sistemas de informação tradicionais, como a complexidade da operação, a adição de novas funcionalidades, a recuperação de erros humanos e a otimização de performance. A imagem abaixo mostra sua estrutura.
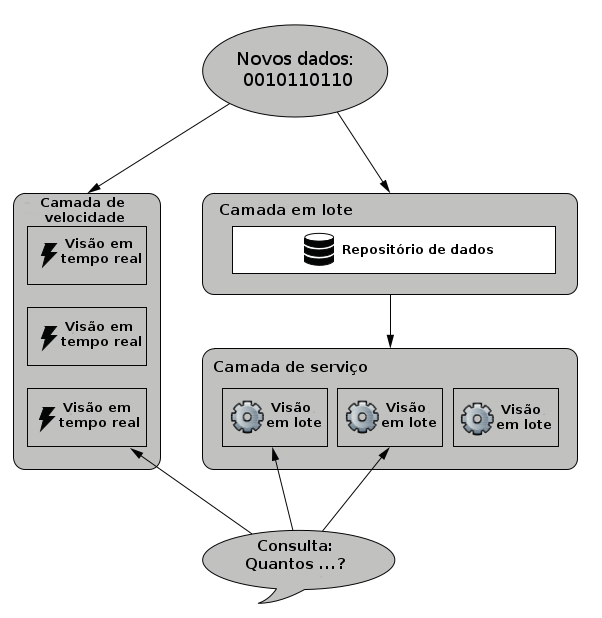
Assim, a Arquitetura Lambda é genérica e pode ser usada em qualquer sistema de informação. Esta arquitetura usa técnicas e ferramentas de big data para processar e armazenar os dados, incluindo tecnologias para o processamento em batch, o banco de dados NoSQL para gerenciamento de dados e o sistema de mensageria para ingestão de dados.
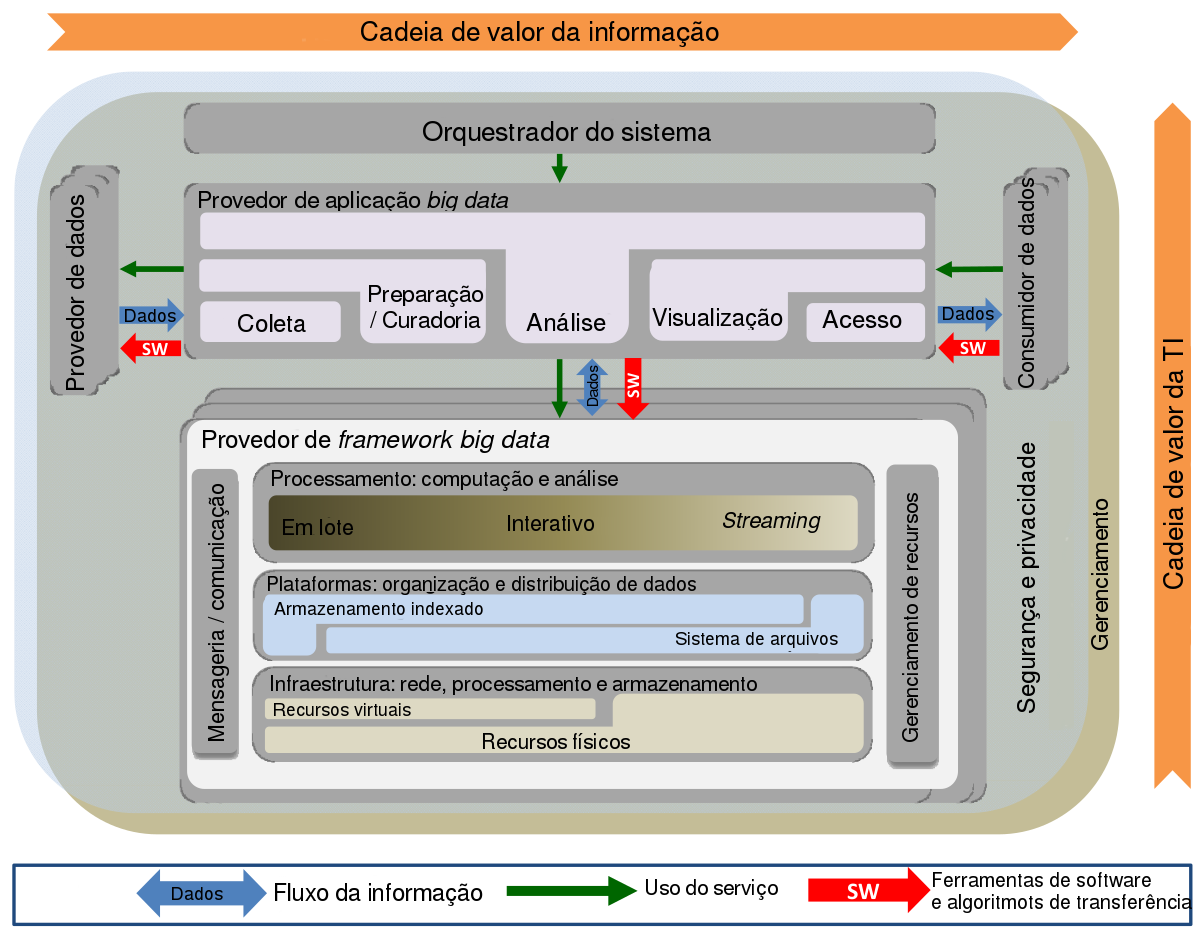
O NIST apresenta algumas outras arquiteturas para big data, desenvolvidas pelas principais empresas de tecnologia como Pivotal, Microsoft e IBM. São arquiteturas para ambientes específicos ou que utilizam tecnologias proprietárias. Em outro estudo, o mesmo NIST apresenta uma arquitetura de referência para big data que pode ser conferida na imagem a seguir e que mostra uma ótima descrição dos conceitos e interconexões entre os componentes dos sistemas de big data.
Conclusão
Neste artigo foi apresentada a arquitetura para sistemas de big data, na qual as análises devem ser feitas preferencialmente em data lakes. Esta é uma tendência que está sendo seguida pelos principais provedores de big data do mercado.
Assim, verificamos que as arquiteturas e frameworks para big data estão se desenvolvendo de acordo com as mudanças na tecnologia e nas demandas de novas soluções para problemas que lidam com uma quantidade crescente de dados. Para tanto, novas alternativas são propostas utilizando processamento distribuído, paralelo e escalável.
Referências
Chang, Wo L. NIST Big Data Interoperability Framework: Volume 5, Architectures White Paper Survey. No. Special Publication (NIST SP)-1500-5. 2015.
Chang, Wo L. NIST Big Data Interoperability Framework: Volume 6, Reference Architecture. No. Special Publication (NIST SP)-1500-6. 2015.
Chen, CL Philip, and Chun-Yang Zhang. “Data-intensive applications, challenges, techniques and technologies: A survey on Big Data.” Information Sciences 275 (2014): 314-347.
Dixon, James. Pentaho, Hadoop, and Data Lakes. https://jamesdixon. wordpress.com/2010/10/14/pentaho-hadoop-and-data-lakes/, 2010.
Hashem, Ibrahim Abaker Targio, et al. “The rise of big data on cloud computing: Review and open research issues.” Information Systems 47 (2015): 98-115.
Marz, Nathan, and James Warren. Big Data. Principles and best practices of scalable real-time data systems. New York; Manning Publications Co., 2015.
Reis, Marco. Uma Arquitetura de Big Data as a Service Baseada no Modelo de Nuvem Privada. Dissertação de Mestrado, Universidade de Brasília, 2018.